Jaké jsou znakové znaky jako ANSI a Unicode a jak se liší?
ASCII, UTF-8, ISO-8859 ... Možná jste viděli tyto podivné monikery, vlastně to znamenají? Přečtěte si, jak vysvětlíme, jaké znakové kódování je a jak tyto zkratky souvisí s prostým textem, který vidíme na obrazovce.
Základní stavební bloky
Když hovoříme o psaném jazyce, hovoříme o tom, že dopisy jsou stavebními kameny slov, které pak vytvářejí věty, odstavce a tak dále. Písmena jsou symboly, které představují zvuky. Když hovoříte o jazyku, mluvíte o skupinách zvuků, které se spojují a tvoří nějaký význam. Každý jazykový systém má složitý soubor pravidel a definic, které řídí tyto významy. Máte-li slovo, je to k ničemu, pokud nevíte, z jakého jazyka pochází a používáte ho s ostatními, kteří mluví daným jazykem.

(Srovnání skriptů Grantha, Tulu a Malayalam, obrázek z Wikipedie)
počítačů používáme termín "charakter". Postava je jakýmsi abstraktním pojmem definovaným specifickými parametry, ale je to základní jednota významu. Latinština "A" není stejná jako řecký "alfa" nebo arabský "alif", protože mají různé kontexty - jsou z různých jazyků a mají mírně odlišné výslovnosti - takže můžeme říci, že jsou to jiné postavy. Vizuální reprezentace znaku se nazývá "glyph" a různé sady glyfů se nazývají písma. Skupiny znaků patří do "sady" nebo "repertoáru".
Když zadáte odstavce a změníte písmo, nezměníte fonetické hodnoty písmen, změníte jejich vzhled. Je to jen kosmetické (ale ne nedůležité!). Některé jazyky, jako starobylé egyptské a čínské, mají ideogramy; to představují celé nápady místo zvuků a jejich výslovnosti se mohou lišit v čase a vzdálenosti. Pokud nahradíte jeden znak jiným, nahrazujete myšlenku. Je to víc než jen měnit dopisy, změní se ideogram.
Kódování znaků

(Obrázek z Wikipedie)
Když na klávesnici napíšete něco nebo načtete soubor, jak počítač ví, co má zobrazit? To je kódování znaků. Text v počítači není ve skutečnosti písmen, je to řada párovaných alfanumerických hodnot. Kódování znaků funguje jako klíč, pro který hodnoty odpovídají, které znaky, podobně jako pravopis, diktuje, které zvuky odpovídají písmenám. Morse kód je druh kódování znaků. Vysvětluje, jak skupiny dlouhých a krátkých jednotek, jako jsou pípnutí, představují znaky. V Morseově kódu jsou znaky pouze anglické písmena, čísla a celé stopy. Existuje mnoho kódování počítačových znaků, které se překládají do písmen, čísel, diakritických znamének, interpunkčních znamének, mezinárodních symbolů apod.
Často se na tomto tématu používá termín "kódové stránky". Jedná se v podstatě o kódování znaků, které používají konkrétní společnosti, často s mírnými úpravami. Kódová stránka systému Windows 1252 (dříve označovaná jako ANSI 1252) je například modifikovanou formou ISO-8859-1. Nejčastěji se používají jako interní systém pro odkazování na standardní a modifikované kódování znaků, které jsou specifické pro stejné systémy. Předčasné kódování znaků nebylo tak důležité, protože počítače mezi sebou nekomunikovaly. Vzhledem k tomu, že internet se stává prominentní a sítí je běžný výskyt, stává se stále důležitějším z každodenních životů, aniž bychom si to dokonce uvědomovali.
Mnoho různých typů
(obrázek od sarah sosiak)
Existuje spousta různých kódovacích kódů a existuje mnoho důvodů. Který znakový kód se rozhodnete použít závisí na tom, jaké jsou vaše potřeby. Pokud komunikujete v ruštině, má smysl používat kódování znaků, které dobře podporuje cyrilice. Pokud budete komunikovat v korejštině, pak budete chtít něco, co představuje Hangul a Hanju dobře. Pokud jste matematik, chcete něco, co má všechny vědecké a matematické symboly dobře reprezentované, stejně jako řecké a latinské glyfy. Jste-li žertík, možná byste měli prospěch z obráceného textu. A pokud chcete, aby všechny tyto typy dokumentů byly zobrazeny jakoukoli konkrétní osobou, chcete kódování, které je docela běžné a snadno dostupné.
Podívejme se na některé z nejběžnějších.

(Výňatek ASCII tabulky, Obrázek z asciable.com)
- ASCII - Americký standardní kód pro výměnu informací je jedním ze starších znaků kódování. Původně byl navržen na základě telegrafických kódů a časem se vyvinul, aby zahrnoval další symboly a některé zastaralé netištěné kontrolní znaky. Pravděpodobně je to tak zásadní, jak můžete získat z hlediska moderních systémů, protože je omezeno na latinskou abecedu bez diakritických znaků. Její 7bitové kódování umožňuje pouze 128 znaků, což je důvod, proč existuje celá řada neoficiálních variant.
- ISO-8859 - nejpoužívanější skupina znaků kódování Mezinárodní organizace pro normalizaci je číslo 8859 Každé konkrétní kódování je označeno číslem, často předponovaným popisným názvem, např ISO-8859-3 (latina-3), ISO-8859-6 (latina / arabština). Je to superset ASCII, což znamená, že první 128 hodnot v kódování je stejná jako ASCII. Je to však 8 bitů a dovoluje 256 znaků, takže se od nich vytváří a zahrnuje mnohem širší pole znaků, přičemž každé konkrétní kódování se zaměřuje na jiný soubor kritérií. Latina-1 zahrnovala spoustu diakritických písmen a symbolů, ale později byla nahrazena revidovaným souborem Latin-9, který obsahuje aktualizované glyfy jako symbol Euro.
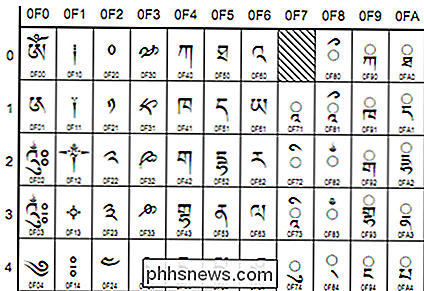
(Výňatek tibetského skriptu, Unicode v4, od unicode.org)
- Unicode - Tento kódovací standard je zaměřen na univerzálnost. V současné době obsahuje 93 skriptů uspořádaných v několika blocích a mnoho dalších v pracích. Unicode pracuje odlišně než jiné znakové sady tím, že namísto přímého kódování pro glyf, každá hodnota je směrována dále na "kódový bod". Jde o hexadecimální hodnoty, které odpovídají znakům, ale samotné glyfy jsou programem odděleny , například webový prohlížeč. Tyto kódové body jsou obvykle zobrazeny takto: U + 0040 (což znamená "@"). Specifické kódování podle standardu Unicode je UTF-8 a UTF-16. UTF-8 se pokouší o maximální kompatibilitu s ASCII. Je to 8bitové, ale umožňuje všechny znaky prostřednictvím substitučního mechanismu a více párů hodnot na jeden znak. UTF-16 příkopy dokonalou kompatibilitu ASCII pro úplnější 16bitovou kompatibilitu se standardem.
- ISO-10646 - Toto není skutečné kódování, jen znaková sada Unicode, která byla standardizována normou ISO. Je to především důležité, protože je to repertoár charakteru, který používá HTML. Některé z pokročilejších funkcí poskytovaných službou Unicode, které umožňují řazení a zprava doleva spolu s skriptováním zleva doprava, chybí. Přesto funguje velmi dobře pro použití na internetu, protože umožňuje použití široké škály skriptů a umožňuje prohlížeč interpretovat glyfy.
Jaké kódování mám použít?
No, ASCII funguje pro většinu anglických reproduktorů, ale ne pro nic jiného. Častěji uvidíte normu ISO-8859-1, která funguje pro většinu západoevropských jazyků. Ostatní verze ISO-8859 pracují pro cyrilské, arabské, řecké nebo jiné specifické skripty. Pokud však chcete zobrazit více skriptů ve stejném dokumentu nebo na stejné webové stránce, UTF-8 umožňuje mnohem lepší kompatibilitu. To také funguje opravdu dobře pro lidi, kteří používají správné interpunkce, matematické symboly nebo znaky mimo manžetu, jako jsou čtverce a zaškrtávací políčka.

(Více jazyků v jednom dokumentu, Screenshot z gujaratsamachar.com)
Existují nevýhod pro každou sadu. ASCII je omezena interpunkčními značkami, takže pro typograficky správné úpravy nefunguje neuvěřitelně dobře. Jakýkoli typ kopírovat / vložit z aplikace Word pouze tak, aby měl nějakou podivnou kombinaci glyfů? To je nevýhoda ISO-8859, nebo správněji, její předpokládaná interoperabilita s kódovými stránkami specifickými pro OS (my se díváme na vás, Microsoft!). Největší nevýhodou softwaru UTF-8 je nedostatečná podpora při editaci a publikování aplikací. Dalším problémem je, že prohlížeče často nevykládají a pouze zobrazují značku pořadí bajtů znaku kódovaného znakem UTF-8. To má za následek zobrazení nežádoucích glyfů. A samozřejmě, deklarování jednoho kódování a používání znaků z jiného, aniž by bylo správně vyhlášeno / odkazováno na webovou stránku, je pro prohlížeče obtížné je vykreslovat správně a vyhledávače je vhodným způsobem indexovat.
Pro vaše vlastní dokumenty, rukopisy apod. Můžete použít vše, co potřebujete, abyste tuto práci vykonali. Pokud jde o web, zdá se však, že většina lidí souhlasí s použitím verze UTF-8, která nepoužívá značku byte, ale to není úplně jednomyslné. Jak vidíte, každé kódování znaků má své vlastní použití, kontext a silné a slabé stránky. Jako konečný uživatel pravděpodobně nebudete muset s tím vypořádat, ale nyní můžete udělat další krok vpřed, pokud si to zvolíte.
Co dělat, když se nedaří připojit k síti Wi-Fi kvůli předchozímu heslu?
Pokud jste noví pracující s sítěmi Wi-Fi, pak změny provedené rodinou nebo přátelé vás mohou nechat v špatné situaci bez připojení. Takže jak se znovu připojujete? Dnešní příspěvek SuperUser Q & A má odpověď, aby pomohl frustrovanému čtenáři, aby se opět připojil ke své síti Wi-Fi. Dnešní zasvěcování o otázce a odpovědi se nám stalo s laskavým svolením SuperUseru - subdivize Stack Exchange, Otázka Otázka čtečka praxe SuperUser chce vědět, jak odstranit staré heslo Wi-Fi a přidat nové: Můj bratr se změnil heslo pro síť Wi-Fi, kterou používám k připojení notebooku k Internetu, když se přestěhoval do jiného města.

Jak na vašem PC hrát své oblíbené hry NES, SNES a jiné retro hry s emulátorem
Viděli jste to. Možná to bylo v letadle, možná to bylo v domě kamaráda, ale viděli jste, že na svých počítačích hrají staré hry Nintendo, Sega nebo dokonce hry PlayStation. A přesto, když jste hledali ty konkrétní hry v Steamu, nic nepřichází. Co je to čarodějnictví? Co jste viděli, můj přítel, se nazývá emulace .