Použití příkazu Najít z příkazového řádku systému Windows

Najít je další skvělý nástroj příkazového řádku, o kterém by měl vědět každý uživatel systému Windows, protože může být použit k vyhledávání obsahu souborů pro konkrétní řetězce textu
Přepínače a parametry hledání
Stejně jako u všech nástrojů založených na příkazovém řádku v systému Windows existují určité přepínače a parametry, které musíte znát, aby byly nástroje efektivně použity.
- / c - Tento přepínač řekne vyhledávacímu nástroji, aby počítal kolik řádků obsahuje vaše
- / i - Tento přepínač říká, že je třeba ignorovat text, který hledáte
- Kromě těchto přepínačů, existují dva parametry, které můžete zadat pomocí tohoto nástroje.
- "String"
- Řetězec budou slova, která hledáte ve svých dokumentech. Musíte vždy pamatovat na to, abyste tuto sekci obklopili uvozovkami, jinak by váš příkaz vrátil chybu.
- Název cesty - Tento parametr určuje místo, které chcete vyhledat. To může být stejně široké jako výpis jednotky nebo jako konkrétní definici jednoho nebo více souborů. Pokud nezadáte cestu, FIND vás požádá o zadání textu nebo může přijímat text pipetovaný z jiného příkazu. Když jste připraveni ukončit manuální zadávání textu, můžete stisknout "Ctrl + Z." O tom budeme diskutovat později.
- Syntaxe Find Stejně jako každý nástroj v okně budete potřebovat vědět jak zadat příkazy.
FIND [SWITCH] "String" [Pathname / s]
V závislosti na vašem příkazu obdržíte jednu ze tří% errorlevel% odpovědí.
1 - Řetězec, který jste hledali, nebyl nalezen
2 - To znamená, že jste měli špatný přepínač nebo vaše parametry byly nesprávné
- Let's Practice
- měli byste si stáhnout naše tři ukázkové textové dokumenty, které budeme používat pro test.
- dokument
ukázka
cvičení
- Tyto dokumenty obsahují text odstavce s několika podobnými skupinami slov. Po stažení těchto tří dokumentů je můžete zkopírovat do libovolné složky v počítači. Pro účely tohoto tutoriálu umístíme všechny tři textové dokumenty na pracovní plochu.
- Nyní budete muset otevřít okno se zvýšeným příkazovým řádkem. Otevřete nabídku Start v systému Windows 7 a 10 nebo otevřete vyhledávací funkci v systému Windows 8 a vyhledejte CMD. Potom klikněte pravým tlačítkem myši na něj a pak stiskněte tlačítko "Spustit jako správce". Ačkoli není třeba otevřít okno se zvýšeným příkazovým řádkem, pomůže vám vyhnout se jakémukoliv otravnému dialogovému oknu.
- několik jednoduchých scénářů, které budou zpracovány níže
Vyhledat jeden dokument pro řetězec slov
Vyhledat více dokumentů pro stejný řetězec slov

Počítat počet řádků v souboru nebo více souborů
- Scénář 1 - Hledání jediného dokumentu pro řetězec slov
- Nyní, když máte uloženy tři dokumenty, zadáme příkaz pro vyhledání textového souboru nazvaného "cvičení" pro slova "martin hendrikx. "Použijte níže uvedený příkaz. Nezapomeňte zadat vyhledávací řetězec do uvozovek a změňte cestu tak, aby odpovídala složce, ve které jsou uloženy vaše dokumenty.
- Najděte "martin hendrikx" C: Users Martin Desktop exercise.txt
žádné výsledky se neobjevily. Nebojte se, nedělali jste nic špatného. Důvod, proč nemáte žádné výsledky, je, že FIND hledá přesnou shodu s vyhledávacím řetězcem. Zkusme to znovu, ale tentokrát přidáme přepínač "/ i" tak, aby VYHLEDÁNO ignoruje případ vyhledávacího řetězce
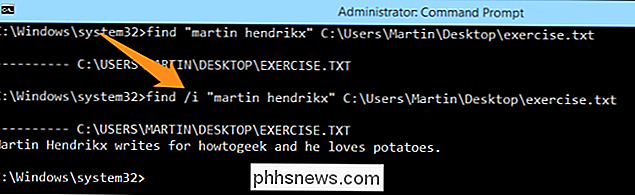
find / i "martin hendrikx" C: Users Martin Desktop exercise.txt
Nyní můžete vidět, že FIND vynesl jeden řádek, který odpovídá vyhledávacímu řetězci, což znamená, že funguje. Zkusme to znovu, ale změňte vyhledávací řetězec na "sushi"; Pokud vaše výsledky vypadají jako obrázek níže, udělali jste to správně.

Scénář 2 - Vyhledejte více dokumentů pro stejný řetězec slov.
Nyní, když víte, jak provést základní vyhledávání, zkuste rozšířit rozsah vyhledávání. Nyní vyhledáme dva textové soubory (cvičení a vzorek) pro termín "sushi". Proveďte to zadáním následujícího řetězce. Nezapomeňte změnit cestu tak, aby odpovídala umístění vašich souborů a přidejte přepínač "/ i" tak, aby vaše vyhledávání nerozlišovalo velká a malá písmena.
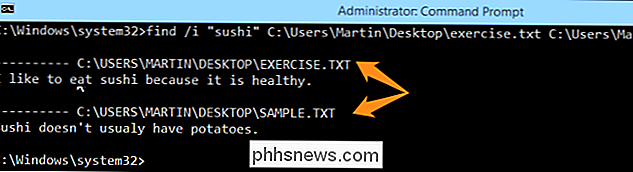
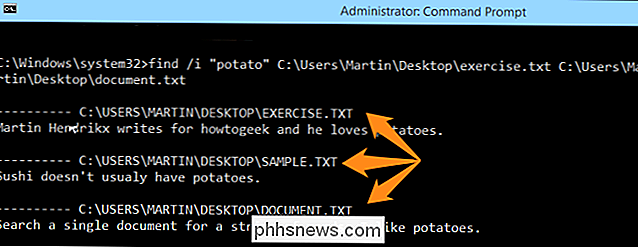
find / i "sushi" C: Users Martin Desktop cvičení. txt C: Users Martin Desktop sample.txt

Všimněte si, že vyhledávací dotazy byly nalezeny v obou dokumentech a vety, ve kterých byly nalezeny, jsou uvedeny pod odpovídajícími názvy souborů a umístění. Zkuste to znovu, ale tentokrát přidejte třetí soubor do příkazu FIND a vyhledejte místo toho slovo "brambor". Výsledky vyhledávání by měly vypadat jako obrázek níže.
Všimněte si, že text nalezený v každém dokumentu je ve skutečnosti "brambory", což znamená, že i když zadáte část slova, uvidíte nějaké fráze obsahující řetězec hledání. Případně můžete pomocí tohoto příkazu zkontrolovat všechny textové soubory.
find / i "sushi" C: Users Martin Desktop * .txt
Scénář 3 - Počítat počet řádků v souboru.
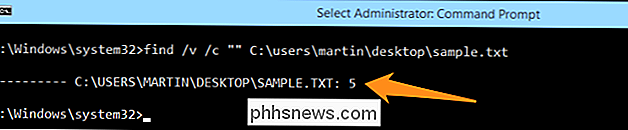
Chcete-li vědět, kolik řádků je v souboru, můžete použít příkaz pro vyhledávání níže. Nezapomeňte přidat mezi všechny přepínače mezeru. V tomto případě nahradíme název cesty s názvem souboru "sample.txt". Pokud chcete jako výsledek jen číslo, použijte tento příkaz:
zadejte C: Users Martin Desktop sample.txt | najít "/ v / c
Pokud chcete číslo a informace o souboru, použijte tento příkaz:
find / v / c" "C: Users Martin Desktop Chcete-li počítat řádky v několika souborech na ploše, použijte následující příkaz:
find / v / c " C: Users Martin Desktop * .txt

různé příkazy a seznámíte se s nástrojem. To může pomoci ušetřit spoustu času v budoucnosti, jakmile vytvoříte systém. Bavte se a pokračujte v geekování.
Image Credit: Littlehaulic na Flickr.com
Jak přizpůsobit Firefox nové rozhraní Quantum
Firefox Quantum je zde a je to plný zlepšení, včetně nového uživatelského rozhraní Photon. Foton nahrazuje rozhraní "Australis", které bylo používáno od roku 2014, a obsahuje mnoho možností přizpůsobení. Což je dobré, protože existuje několik nepríjemností - jako prázdný prostor na obou stranách lišty URL.

Jak připojit Nest bezpečnou k nové síti Wi-Fi
Pokud někdy změníte heslo Wi-Fi nebo název sítě, budete muset také připojit svůj Nest Zabezpečte zabezpečení této nové sítě. Naštěstí je to opravdu snadné. SOUVISEJÍCÍ: Jak změnit zpoždění alarmu pro Nest Secure Mnoho zařízení Wi-Fi má nastavení, ve kterém můžete snadno změnit síť Wi-Fi, připojen k. Jiné zařízení nejsou tak jednoduché a musíte je skutečně vynulovat pouze proto, aby se připojily k nové síti Wi-Fi.